负载均衡
# 负载均衡
只要是并行问题,都会遇到负载均衡。好比把活分给不同的人,有的干得快,有的干得慢;分给效率相同的人的时候,分的方案不合理,也会导致有的分的活多,有的分的活少。于是大家不同步,导致效率高的要等效率低的完成后,才能进行下一步。
多数情况下,大家关心的是均匀体系,用的CPU的效率也基本相同,所以不用担心负载均衡问题。但,体系是气液界面体系、有真空区的固体、体系密度不均匀等时,可能需要用到LAMMPS提供的负载均衡命令。

当你调用N个cpu cores运行LAMMPS时,LAMMPS会把你的simulation box划分成N个小区域,再把每个区域内的原子分派给这N个cpu cores。 默认情况下,整个box会被尽可能均匀的划分。以2d square box为例,用16个核运行时,默认的cpu划分方式如下图:

如果整个box都均匀的填满了原子(例如模拟周期性的晶体),默认的cpu划分方式效率是不错的。但如果box内原子的分布并不均匀,这种划分方式就会导致部分cpu负载高,部分cpu负载低甚至是空负载。假如实际模型是上图中的L型结构,默认划分的并行效率绝不会超过50%。
因此LAMMPS提供了两个负载均衡命令,一个是静态负载均衡(balance),在模拟之初先根据初始结构特点设置好负载均衡,后面计算的时候也不改变;一种是动态负载均衡,在模拟过程中根据参数动态调整计算的均衡性(fix balance)。
balance是一个通用命令,只会在脚本执行到这个命令得时候执行一次;而fix命令可以在运行过程中按照设定得频率反复执行,因此fix balance实际上是在执行得过程中反复执行balance这个操作。
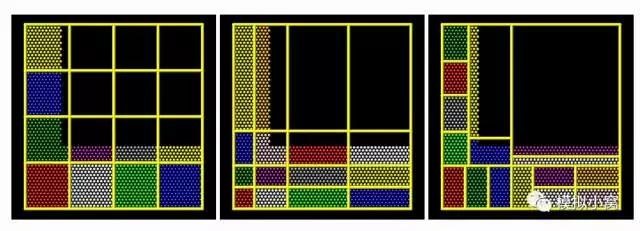
shift模式属于grid方法,把默认的图3左一(等间距分割),根据参数搞成b图(不等间距分割);rcb模式是tiling方法,类似于不同大小的砖块堆积(每个砖块类似于个cpu),把负载进行划分。看着似乎图三右一比较合理。但这儿需要的通信模式设置是不同的。“The “grid” methods can be used with either of thecomm_style command options, brick or tiled. The “tiling” methods can only be used with comm_style tiled.” 除了需要满足的更新频率(Nfreq)外,另外一个条件也需要满足才会rebalance,就是thresh 有两个一种是no-weight方式,按粒子数均分到各个cpu上,一种是weight方式,按相同的computational weight进行分配。
这个时候,你可以用balance命令来手动/自动优化cpu的划分方式,让每个cpu的负载尽量均衡,从而提高并行效率。 例如:
comm_style tiledfix fixbalance all balance 1000 1.2 rcbrun 100000
在用了上述命令之后,上图中的box大概会被划分成这种结构:
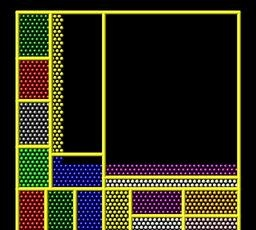
其中,comm_style tiled 命令将cpu通信方式从默认的brick style (图2中的对齐式)换成tiled style (图3中的非对其式)。 而
fix fixbalance all balance 1000 1.2 rcb
命这个令,则为整个体系(all)创建了一个名为fixbalance(这个名字可以随便取)的动态cpu负载balance策略:每隔1000步进行一次判断,若判断时某个cpu的负载超出了平均值的1.2倍,就重新进行cpu划分,使负载更加均衡,否则维持当前划分方式。
从个人经验来看,balance这个命令对原子密度分布不均匀的体系(例如包含真空层的体系)效果非常显著。以我最近算的一个拉伸体系为例,原子模型一般长这样:

由于模型中存在大体积的真空区域,默认的cpu划分效率不高。在使用单节点40核的情况下,模拟速度通常为20 timesteps/s左右。并且,因为我用了shrink wrapped boundary,试样断裂时可能有碎片飞出,盒子会自动扩大以容纳碎片,此时的模拟速度甚至降低到了10 timesteps/s以下。 而使用了上述balance后,模拟速度基本上稳定在30 timesteps/s,收获了超过50%的速度提升。
还是那一句老话,对于不清楚的参数,默认的总是最好的。只有出现了迫切的需求,比如非常稀疏的体系,在认真研究机理之后才会有好的优化效果。